Let's start to collect data to TreasureData
1. First Step to TreasureData
When you start to use TreasureData, you will need to take care of the following things in short.
- Collect Data
- Query Data
- Visualize Data
This page describes a first step to collect data to TreasureData.
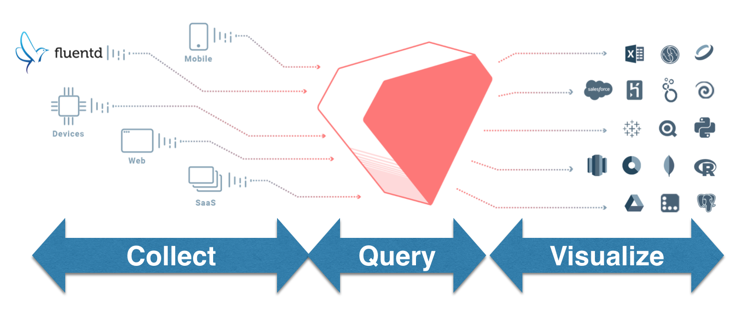
1.1. Category of collecting
At first, you have to plan how you collect data from own data sources. But, there are several types of data source.
You can categorize the way of collecting data to TreasureData into several ways.
You want to import data from ...
- Web Application on Backend (Java, Rails, Node, PHP, ...)
- Web Application on Frontend (Javascript, ...)
- Message Queue System (Kafka,AWS Kinesis, ...)
- Cloud Storage (AWS S3, Google Cloud Storage, ...)
- Database (MySQL, PostgreSQL, ...)
- Moblie Application (iOS, Android, ...)
- External Cloud Services
By the way, You DON'T need to set schema for table before importing data. This is enable by schema-on-read feature, which is one of important feature on TreasureData.
So, please check which is suitable for your system, and make the next step forward through these related documents.
2. Let's collect data from ...
2.1. Web Application on Backend
When you import data from web application on backend, the architecture would be the following 2 patterns.
2.1.1. Only Forwarder Case
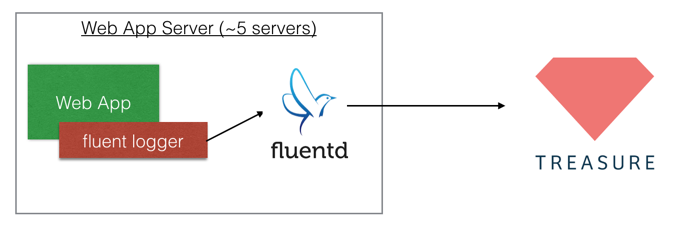
This architecture is simple. You need to embed Fluent Logger into your web app and install fluentd into your web app server. Then, you can upload any data to TreasureData per a few second ~ a minute.
Regarding to Fluent Logger, it's implemented by each language. So, you can choose any Fluent Logger.
Next Step
- See Fluent Logger
2.1.2. Forwarder - Aggregator Case
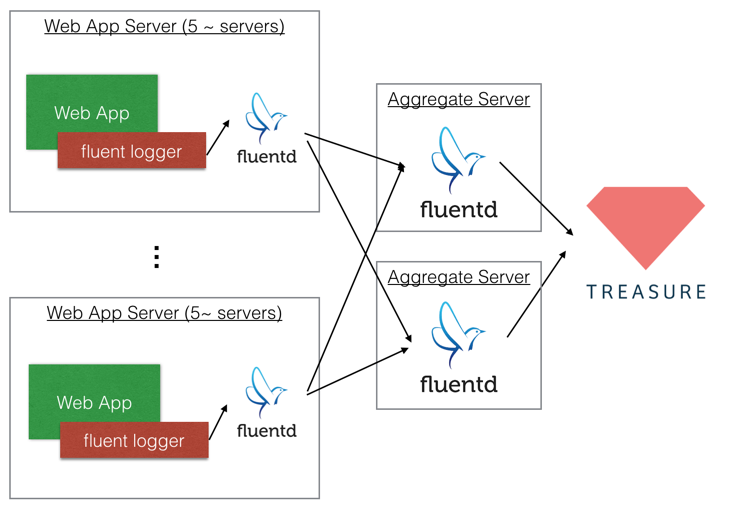
This architecture is built 2-stage structure by forwarder and aggregator. Forwarders focus to transfer data to aggregators, because forwarder should not be use too much resources by fluentd. Aggregators applies any filters and additional plugin, and send data to TreasureData. If you want to change any filters, you can change config of only aggregators.
Next Step
- See an example of fluentd's forwarder and aggregator config. -- Fluentd High Availability Configuration
2.2. Web Application on Frontend
If you want to collect data from Frontend like Google Analytics, you can embded Javascript SDK into your web. Also, you can use Google Tag Manager for Javascript SDK.
Next Step
- You can see the detail on the following documents.
2.3. Message Queue System
As you know, Message Queue System is useful to scale up the rate with which messages are added to the queue or processed. Each system has a individual way to output data to TreasureData.
2.3.1. Apache Kafka
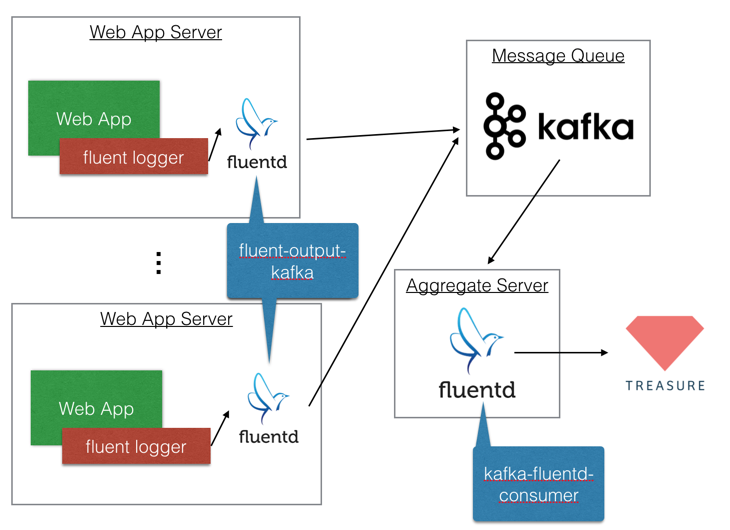
If you want to use Apache Kafka, your architecture would be the above.
In order to push data to Kafka from web app servers via fluentd, you need to use fluent-output-kafka. After buffering data on Kafka, you can pull data by using kafka-fluentd-consumer.
Next Step
2.3.2. Amazon Kinesis
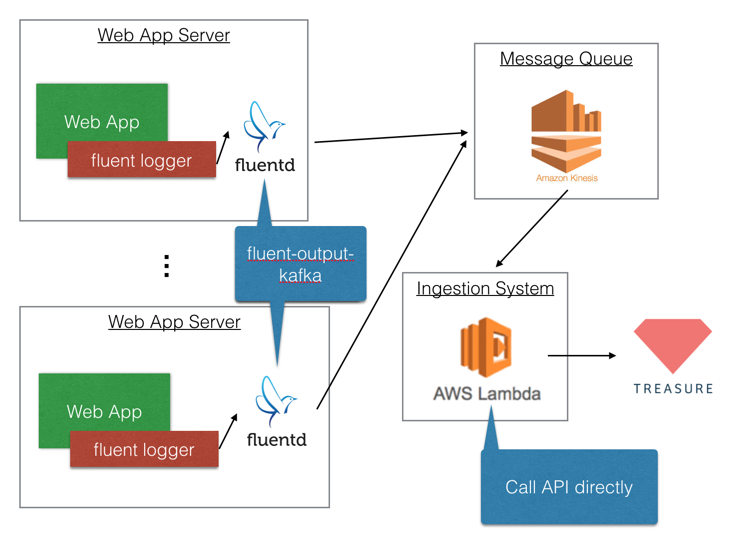
In order to collecting from Amazon Kinesis, you need to use AWS Lambda due to calling API directly. The following official document shows how to use it by Python. If you want to do same thing by Java, you can do it by using td-client-java.
Next Step
- See official document
- Also, see Github
2.3. Cloud Storage
I know that you love to store data on AWS S3 and Google Cloud Storage. Surely, TreasureData is able to collect data from them by 2 types of tool; Pull type and Push type.
2.3.1. Pull Type; DataConnector
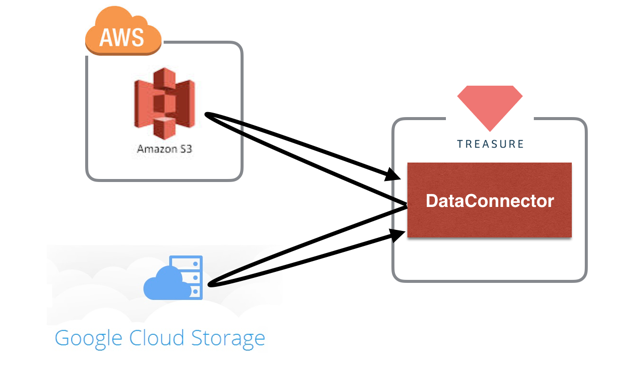
DataConnector is TreasureData's hosted data loader. By using DataConnector, you don't need any additional servers to upload data. You just put data (Ex. csv, tsv, csv.gz,...) to cloud storage, and prepare a credential for DataConnector. Then, DataConnector can ingest your data from cloud storage.
Next Step
- See official documents
2.3.2. Push Type; Embulk (or BulkImport)
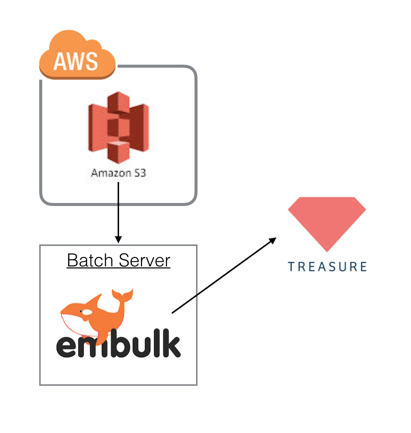
Embulk is a open-source bulk data loader that helps data transfer between various databases, storages, file formats, and cloud services. If you couldn't allow TreasureData to access directly, it would be nice to use Embulk. But, you need to setup it on own server as batch server.
NOTE: TreasureData provides similar tools; Embulk and Bulkimport. Bulkimport is embeded into td command. But, it might be deprecated, will not be updated. Because, Embulk is fixed several issues of BulkImport. So, I suggest you to use Embulk instead of Bulkimport.
Also, DataConnector's core system is build by Embulk.
Next Step
2.4. Database
Your service must have master data on databases; MySQL, PostgreSQL, Redshift, etc.. In this case, you can use same tool as Cloud Storage. Also, you need to check accessibility to databases.
2.4.1. Public Access; DataConnector
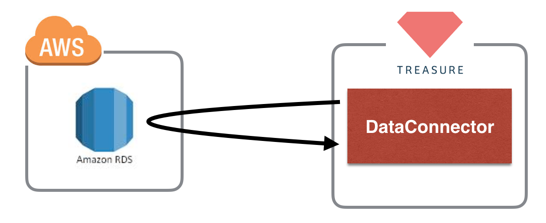
DataConnecto can collect data from several databases. So, if you can provide credential, you can use DataConnector.
If you have any concerns about security, TreasureData has 2 options; SSL and StaticIPs for DataConnector.
If you need more additional secruity, it would be better to use Embulk.
Next Step
2.4.2. Private Access; Embulk (or BulkImport)
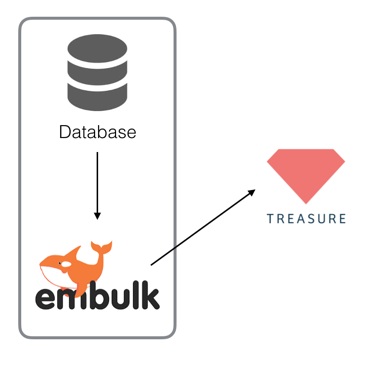
If you couldn't allow TreasureData to access to you DB directly, it would be nice to use Embulk too. Embulk has a JDBC plugin, so if you have a paid RDB; Oracle and SQL Server, you should use Embulk too.
Next Step
2.5. Mobile Application
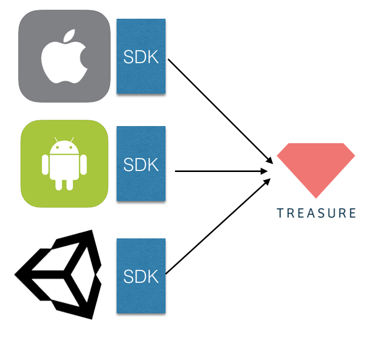
TreasureData provides mobile SDKs. Though integration them, you can import data on your application into Treasure Data without building your servers.
Next Step
2.5.1 Postbacks
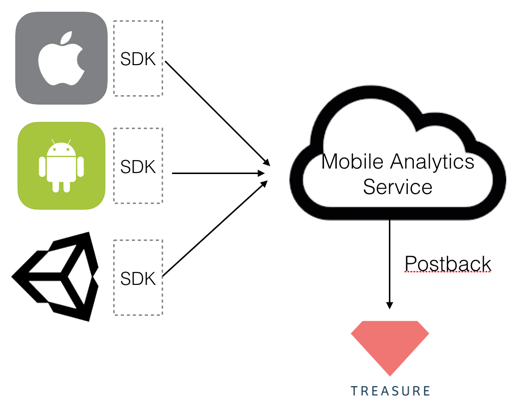
I know you already embed several tools into your mobile apps. It might be hard to add TreasureData SDK into your mobile apps due to size or extra work. But, TreasureData has a postback feature betwen several mobile analytics service. If you setup it on mobile analytics service, you can transfer data to TreasureData with adding few codes.
The reason is why you use an extra analytic service as TreasureData. Because, general mobile analytics services doesn't allow users to access raw data. But, if you use this postback feature, you can access to rawdata on TreasureData.
Next Action
- Raw-Data Access to Adjust Events
- Raw-Data Access to AppsFlyer Events
- Raw-Data Access to Kochava Events
- Raw-Data Access to TUNE Events
- Realtime SQL Access for Segment
2.6. External Cloud Services
DataConnector has a feature to collect data from external cloud services. Through collecting these data, data from external cloud services collaborate with own application data.
If you want to integrate any other services, it would be nice to check this page, and click a logo you want to collect.
Conclusion
This page is just a first step for finding your suitable import tools. I'll show each best practice on another page.
Look forward to it!!